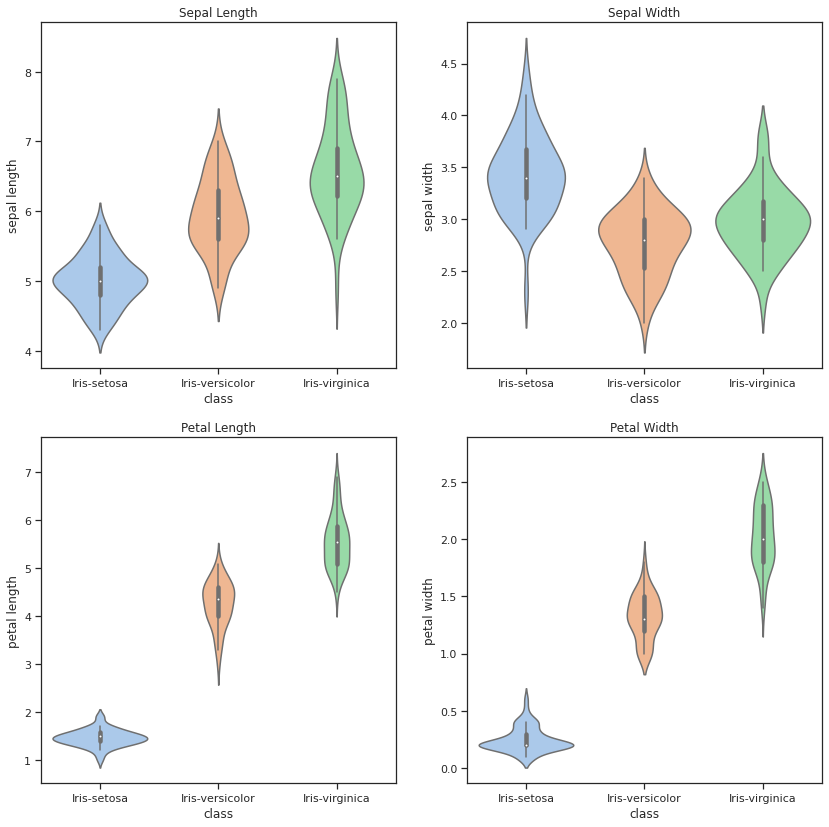
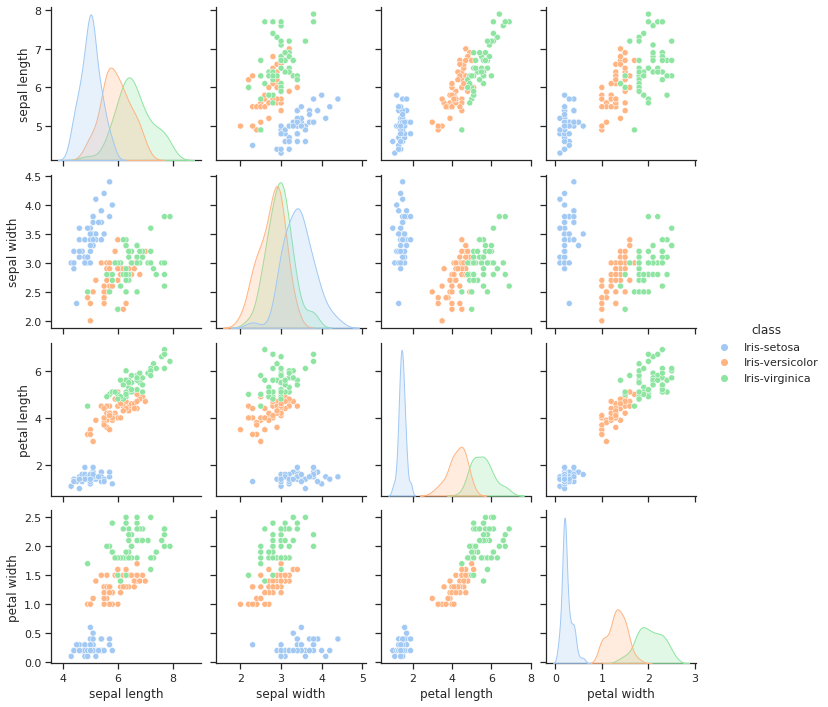
The Iris Data set was created by R.A. Fisher and is perhaps the best known data set to be found in the pattern recognition literature. Fisher’s paper is a classic in the field and is referenced frequently to this day. The data set contains 3 classes of 50 instances each, where each class refers to a type of iris plant. Predicted attribute: class of iris plant.
This article aims to classify this dataset utilizing the following models: K Nearest Neighbors (KNN), Naive Bayes and Logistic Regression.
You can find the data source and Iris Dataset Analytics.py here.
import matplotlib.pyplot as plt
import seaborn as sns
features = ["sepal length", "sepal width", "petal length", "petal width"]
sns.set(style="ticks", palette="pastel")
f, axes = plt.subplots(2, 2, sharey=False, figsize=(14, 14))
for ind, val in enumerate(features):
sns.violinplot(x="class", y=val, data=df, ax=axes[ind // 2, ind % 2]).set(
title = "Sepal Length"
)
plt.show()
sns.pairplot(df, hue="class")
Train and evaluate three models using cross-validation
K-Nearest Neighbors Classifier
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import ShuffleSplit
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.model_selection import GridSearchCV
NUM = 200
X = df.drop(["class"], axis=1)
y = df["class"]
shuffle = ShuffleSplit(n_splits=NUM, test_size=0.25, random_state=10)
results = []
klist = np.arange(1, 21, 1)
FullModel = Pipeline([("scaler", StandardScaler()), ("knn", KNeighborsClassifier())])
param_grid = {"knn__n_neighbors": klist}
grid_search = GridSearchCV(
FullModel,
param_grid,
scoring = "accuracy",
cv = shuffle,
return_train_score = True,
n_jobs = -1,
)
grid_search.fit(X, y)
results = pd.DataFrame(grid_search.cv_results_)
print(
results[
[
"rank_test_score",
"mean_train_score",
"mean_test_score",
"param_knn__n_neighbors",
]
]
)
rank_test_score
mean_train_score
mean_test_score
param_knn__n_neighbors
0
18
1.000000
0.943947
1
1
20
0.970268
0.937368
2
2
17
0.959018
0.945132
3
3
15
0.958214
0.945789
4
4
12
0.963304
0.949737
5
5
9
0.963080
0.952105
6
6
6
0.966741
0.954605
7
7
3
0.962500
0.955395
8
8
7
0.963482
0.954474
9
9
5
0.963571
0.955000
10
10
2
0.965536
0.956447
11
11
1
0.965982
0.958553
12
12
4
0.963973
0.955132
13
13
8
0.963661
0.954079
14
14
11
0.961205
0.950000
15
15
10
0.959107
0.950658
16
16
14
0.957143
0.946711
17
17
13
0.956205
0.947895
18
18
16
0.955223
0.945526
19
19
19
0.953036
0.942895
20
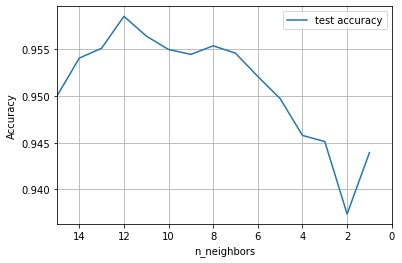
# Plot Accuracy vs K
fig, ax = plt.subplots()
ax.plot(
results["param_knn__n_neighbors"], results["mean_test_score"], label="test accuracy"
)
ax.set_xlim(15, 0) # reverse x; from simple model to complex model
# (complex model tries hard to sort of figure out all sorts of details in the data)
ax.set_ylabel("Accuracy")
ax.set_xlabel("n_neighbors")
ax.grid()
ax.legend()
Naive Bayes Classifier
from sklearn.naive_bayes import MultinomialNB
from sklearn.preprocessing import MinMaxScaler
features = ["sepal length", "sepal width", "petal length", "petal width"]
df1 = df.copy()
for column in features:
df1[column] = [round(i - np.min(df1[column])) for i in df1[column]]
df1[column] = df1[column].astype("category")
X = pd.get_dummies(df1[features])
# Calculate mean test accuracy
alphas = [0.01, 0.1, 1.0, 5.0, 10.0, 15.0, 20.0, 35.0, 50.0]
FullModel = Pipeline([("scaler", MinMaxScaler()), ("mnb", MultinomialNB())])
param_grid = {"mnb__alpha": alphas}
grid_search = GridSearchCV(
FullModel,
param_grid,
scoring = "accuracy",
cv = shuffle,
return_train_score = True,
n_jobs = -1,
)
grid_search.fit(X, y)
results = pd.DataFrame(grid_search.cv_results_)
print(
results[
["rank_test_score", "mean_train_score", "mean_test_score", "param_mnb__alpha"]
]
)
For the current running, Logistic Regression has the highest test accuracy followed by KNN Classifier. Naive Bayes Classifier has the lowest test accuracy.